

Data Masking vs Tokenization
The way we use data has dramatically changed, pushing technology forward in exciting ways. However, keeping that data safe is more important than ever. The real challenge of data security is protecting all those bits and pieces of sensitive information from falling into the wrong hands. As we’ve come to rely more on data, we’ve also started to understand just how valuable – and vulnerable – it really is. Data isn’t just numbers and facts anymore; it’s insights and secrets that can shape entire industries. But with great potential comes great risk. If sensitive information gets out or is targeted by hackers, the damage can be huge. To keep data safe, techniques like data masking and tokenization are crucial. They help prevent data breaches and hide the real details from those with unauthorized access while keeping data usable, each in its own unique way, ensuring our secrets stay secure.
Understanding Data Masking
Data masking swaps the original sensitive data with fictitious yet structurally similar data. This alternate set of data is then used in place of the original, sensitive data set. This way, if the data were to fall into the wrong hands, the sensitive information would still be safe because the substitute version has no real value.
Data masking is implemented in two primary forms: static data masking (SDM) and dynamic data masking (DDM). Each is an essential strategy for securing sensitive information tailored to different scenarios and needs.
- Dynamic data masking focuses on securing data in real time, ensuring that unauthorized users encounter only obfuscated data. This approach does not alter the actual data; instead, it provides a masked view to users not cleared to see the real information, making it ideal for real-time testing purposes while preserving the referential integrity of the data.
- Static data masking is designed for use in non-production environments. It involves creating a sanitized copy of the production data where the sensitive values are replaced with fictitious but realistic counterparts. This method is particularly useful when data needs to be shared externally or with internal teams who require access to data structures but not the sensitive data itself. By replacing sensitive data with realistic but fake data, static data masking ensures that the original data’s confidentiality is maintained while still allowing for meaningful development, testing, or training activities.
So, when do organizations use data masking?
Organizations will use data masking to keep and conceal sensitive info such as social security numbers and credit card numbers, along with other personally identifiable information (PII) from unauthorized access. This protection is essential for preserving data privacy during software testing and for adhering to regulatory compliance requirements. Through data masking techniques like data obfuscation and the use of SQL servers, data masking effectively maintains data security, ensuring that an organizations masked data remains safe.
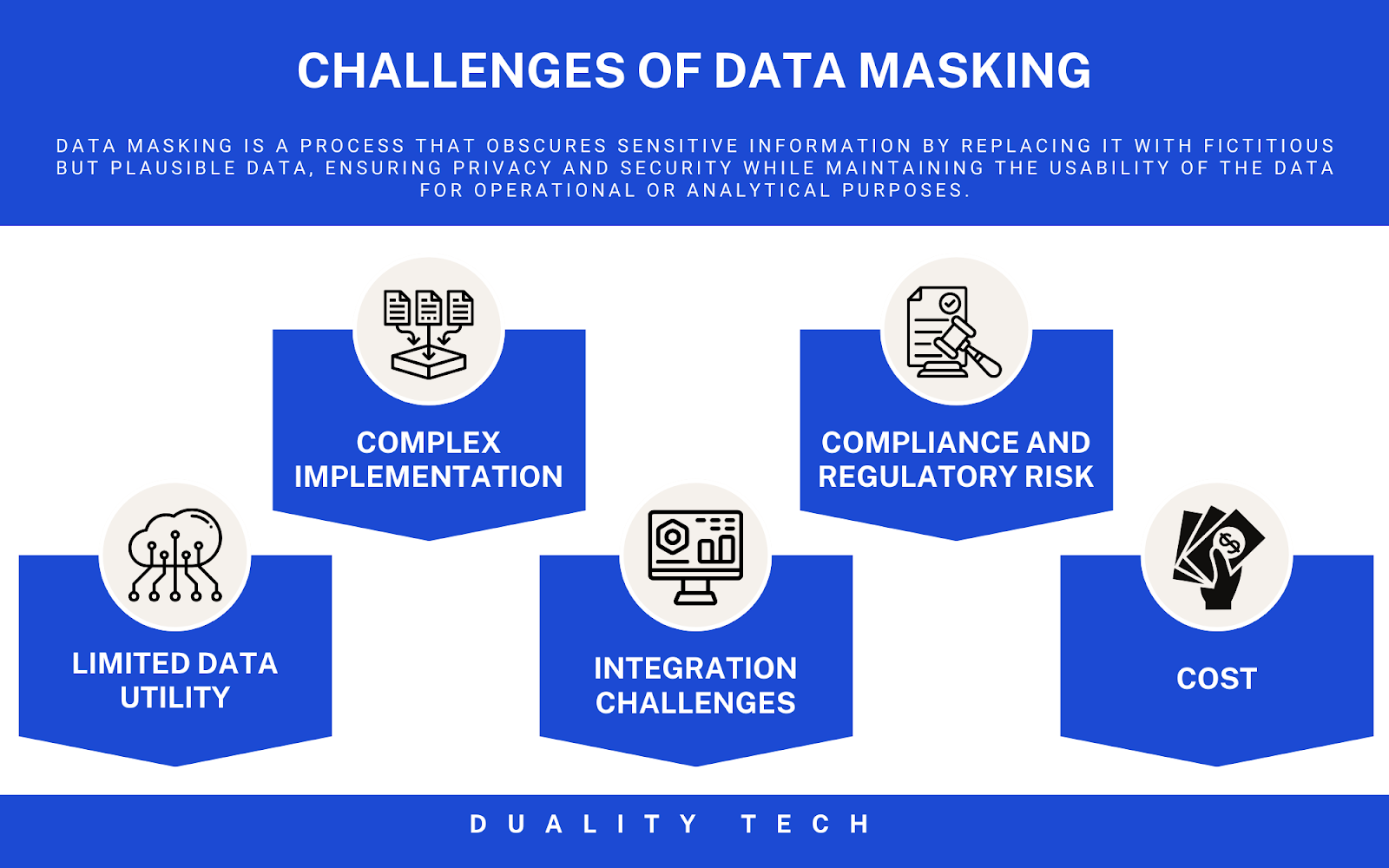
But, just like with anything, it’s not a perfect process. On one hand, it’s great for keeping data safe during testing or analytics scenarios where sensitive data elements aren’t crucial and you don’t need the nitty-gritty details of the original data. On the other hand, sometimes the masked data isn’t as useful as the real data, especially if you need the full data to gather information later on. Additionally, the implementation of data masking can be complex, costly, and requires constant maintenance and management. Ultimately, data masking is not a standalone solution but should be viewed as part of a broader, comprehensive data security strategy.
Understanding Data Tokenization
Tokenization is the process of substituting sensitive data elements with randomly generated data strings known as “tokens.” These tokens interact within your systems, databases, and applications as representatives of the original data set. The true information is securely stowed away in a heavily encrypted ‘token vault.’ Tokens lack inherent meaning and cannot be reverse-engineered to unveil the original data they symbolize. The original data can only be retrieved by utilizing the system that generated the token, a process referred to as de-tokenization.
Tokenization is typically used by organizations to enhance the security of sensitive information such as credit card information, personal identification numbers, and other PII. The tokenization process is flexible and is used in various scenarios ranging from payment processors and payment gateways to protecting healthcare records and aiding AI model training. Tokenization minimizes the amount of sensitive data that falls under regulatory requirements. Because the sensitive data is replaced with non-sensitive tokens, the actual data is not stored or processed by an organization’s systems. This means fewer systems are handling sensitive information, therefore reducing the scope of what needs to be secured and compliant with regulations such as the PCI DSS (Payment Card Industry Data Security Standard) for cardholders’ sensitive data.
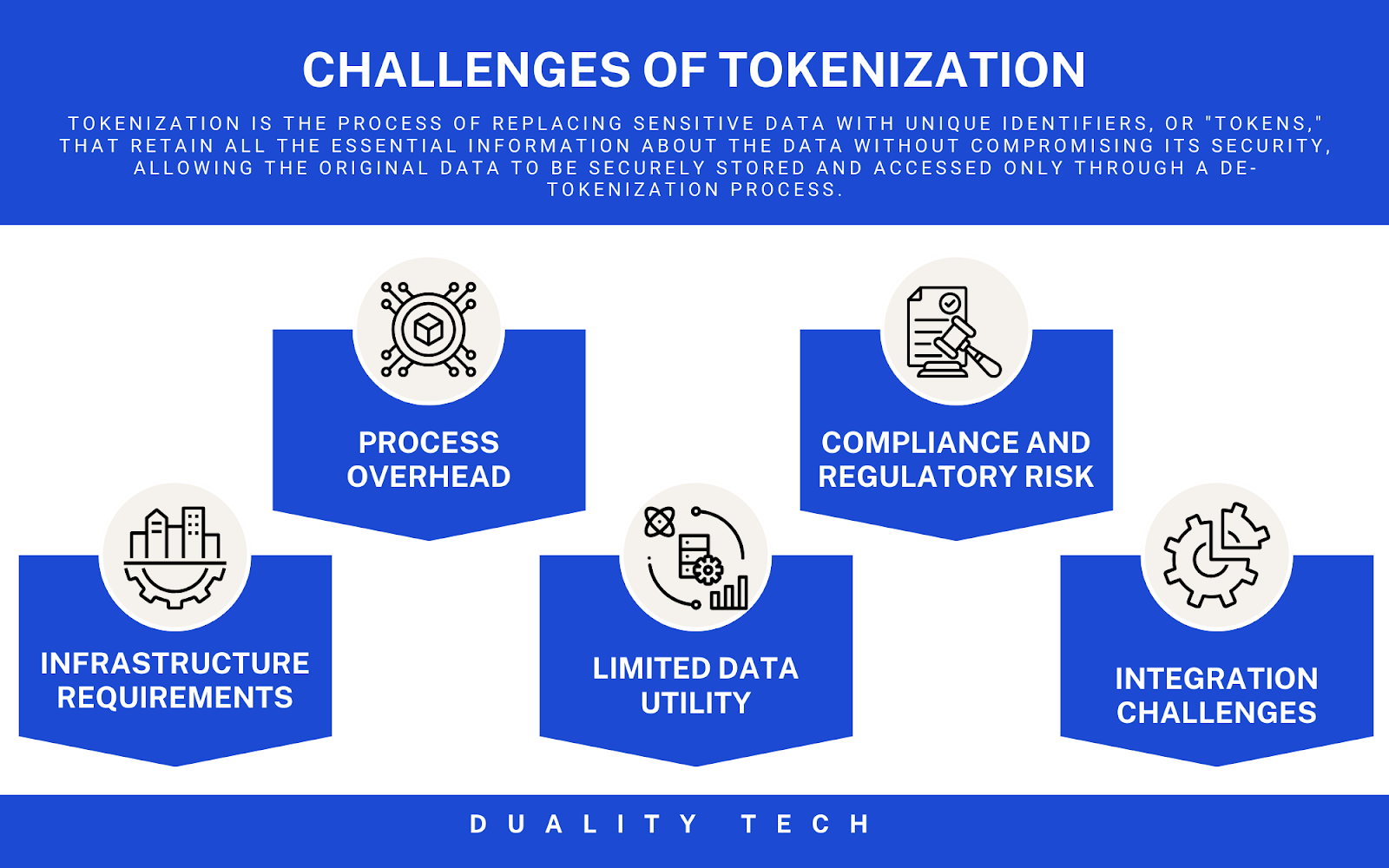
But, there are still some challenges. Tokenization requires a specific infrastructure for implementation, which can present technical challenges and may slow down some processes due to the potential overhead of tokenization and de-tokenization. And while it makes data a lot safer, it’s not a silver bullet. In some cases, tokenization could limit data utility and it does not eliminate regulatory risk entirely. If an attacker gains access to the tokenization system, tokens can be exchanged back into the original value.
As expected, there is not a single strategy that holds a monopoly on data security, and instead the secret lies in understanding the benefits and limitations of each approach, and deciding which data security method works best for you.
Comparing Data Masking and Tokenization
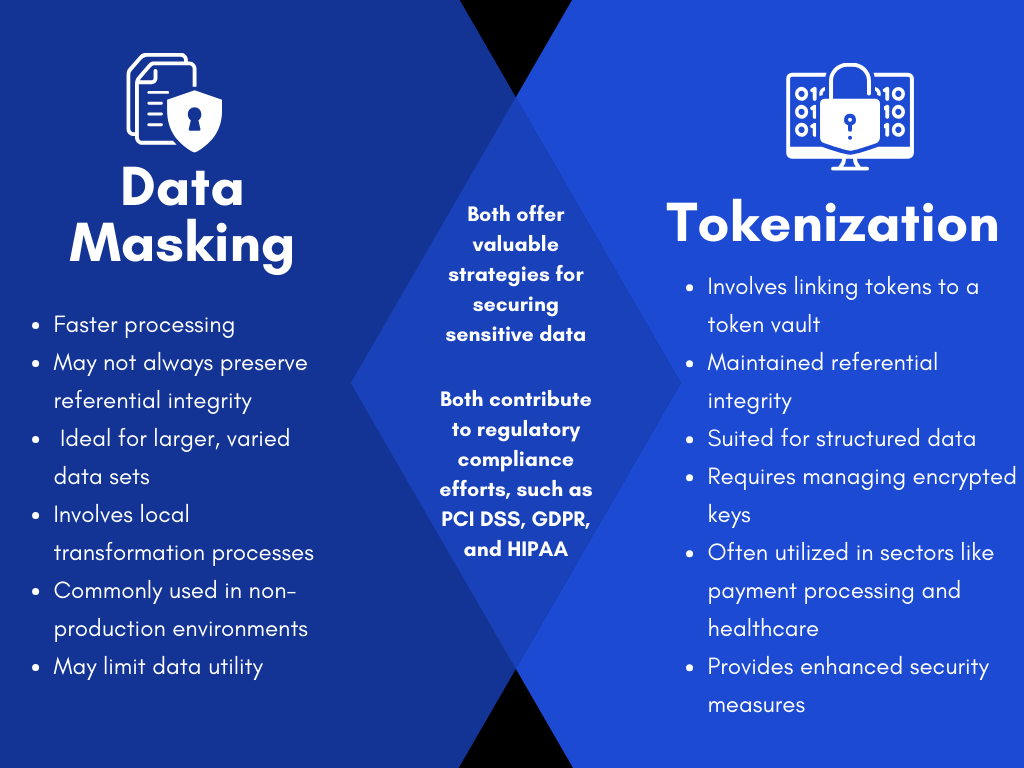
So, how do you decide which data privacy method to use? Consider measures like performance, impact on referential integrity, and the scope of sensitive data that can be protected.
Performance
Data masking is generally faster since it often handles data locally, on the same database. Tokenization, on the other hand, requires the token to be linked to a token vault stored elsewhere, creating a delay in the process.
Referential Integrity
Tokenization is able to safeguard the data relationships more effectively than data masking. Each unique sensitive data element corresponds to a unique token, and this relationship is upheld as tokens replace the actual data in every instance. In contrast, data masking might not always preserve referential integrity, especially if different transformations are performed on the same data in different tables.
Scope
Data masking proves more useful when dealing with a larger varied data set. It’s flexible and adaptive, dealing with structured or unstructured data with ease. Tokenization, conversely, is better suited for structured data, especially when dealing with specific sensitive data.
Leveraging Encryption Keys
The methods diverge significantly in their use of encryption keys. Here, the trade-off emerges between speed and security. Tokenization depends on external mechanisms and encryption keys for securing data, which, while potentially slower, provides enhanced security. Data masking operates locally without the need for external function and encryption keys, offering quicker data processing but potentially sacrificing a level of security compared to tokenization.
Understanding the differences between data masking and tokenization – and figuring out which one suits your data security needs – is crucial to deciding the right data security method for your needs. Each method has its own way of keeping sensitive data safe, and how well they work depends on what you’re trying to achieve. You’ve got to take a good look at what your project or task demands, from the nitty-gritty tech specs to the big-picture security goals, to choose the best way to protect your important info.
Why is Duality Better for Data Privacy than both Data Masking and Tokenization?
Data security is about a balance between utility, risk, and compliance. While both data masking and tokenization offer unique advantages in securing sensitive data, Duality Tech facilitates data protection with our innovative use of encryption to secure data “in use”, while complying with data privacy regulations. Our use of Fully Homomorphic Encryption (FHE) allows computation directly on encrypted data without needing to decrypt it first. This way, sensitive data remains encrypted at all times. In doing this, Duality offers a solution that eliminates many of the limitations faced by data tokenization and data masking, combining privacy with utility.
Why does it matter? Data security is not simply a box to check. It is an integral component of a business’s operations. The right data privacy strategy can boost your brand’s trustworthiness, ensuring your corporate reputation is protected while facilitating the efficient use of data and the wrong data privacy method can result in significant consequences, including breaches, loss of customer trust, legal liabilities, and damage to your brand’s reputation. That’s why partnering with Duality Tech is essential for proper data security management.
At the intersection of cryptography and data science, Duality Tech stands as an expert in operationalizing Privacy Enhancing Technologies (PETs). Created by globally recognized cryptographers and specialist data scientists, Duality equips organizations with the tools necessary for secure collaboration on sensitive data. Our credibility is not just based on claims. Rather, it is reinforced by strong partnerships with leading industry and government organizations like AWS, DARPA, Intel, Google, Oracle, IBM, and the World Economic Forum (WEF) who entrust us to maximize the value of their data.
By understanding the benefits and limitations of different data security methods, and seeking an experienced partner like Duality Tech, organizations can achieve a stronger, more nuanced approach to data privacy.



