

AI is moving beyond single-organization deployments. Some of the most pressing use cases today include financial crime prevention, cross-border health research, and drug discovery that depend on data that no single party controls. For example, each bank on its own may not have enough data to train an effective fraud detection model, but by pooling intelligence across institutions they can identify cross-institutional fraud patterns. Similarly, medical centers studying cancer or rare diseases achieve better accuracy by training on larger, combined datasets but privacy and regulatory barriers often prevent this type of collaboration.
At the same time, regulatory requirements such as the EU AI Act, GDPR, and HIPAA make centralizing sensitive data increasingly risky or outright impossible. This creates a critical need: how to use distributed, sensitive, and regulated data for AI without compromising privacy or compliance.
Federated Learning as a Foundation
To solve this challenge, Federated Learning (FL) has become one of the most powerful approaches for training AI models on distributed data. In standard FL, computation takes place locally: each participant trains a model on their own dataset and shares only intermediate results (model updates) with a central server for aggregation. This allows models to benefit from diverse data without raw data ever leaving its source.
However, even though raw data isn’t shared, those local updates can still leak sensitive information, especially if aggregated repeatedly or probed by adversaries. This is a key limitation for industries where data is both highly sensitive and strictly regulated.
Duality addresses this by embedding Privacy Enhancing Technologies (PETs) directly into the FL lifecycle. These PET layers extend the security guarantees of standard FL and enable organizations in healthcare, finance, government, and other regulated sectors to collaborate safely.
Secure Aggregation
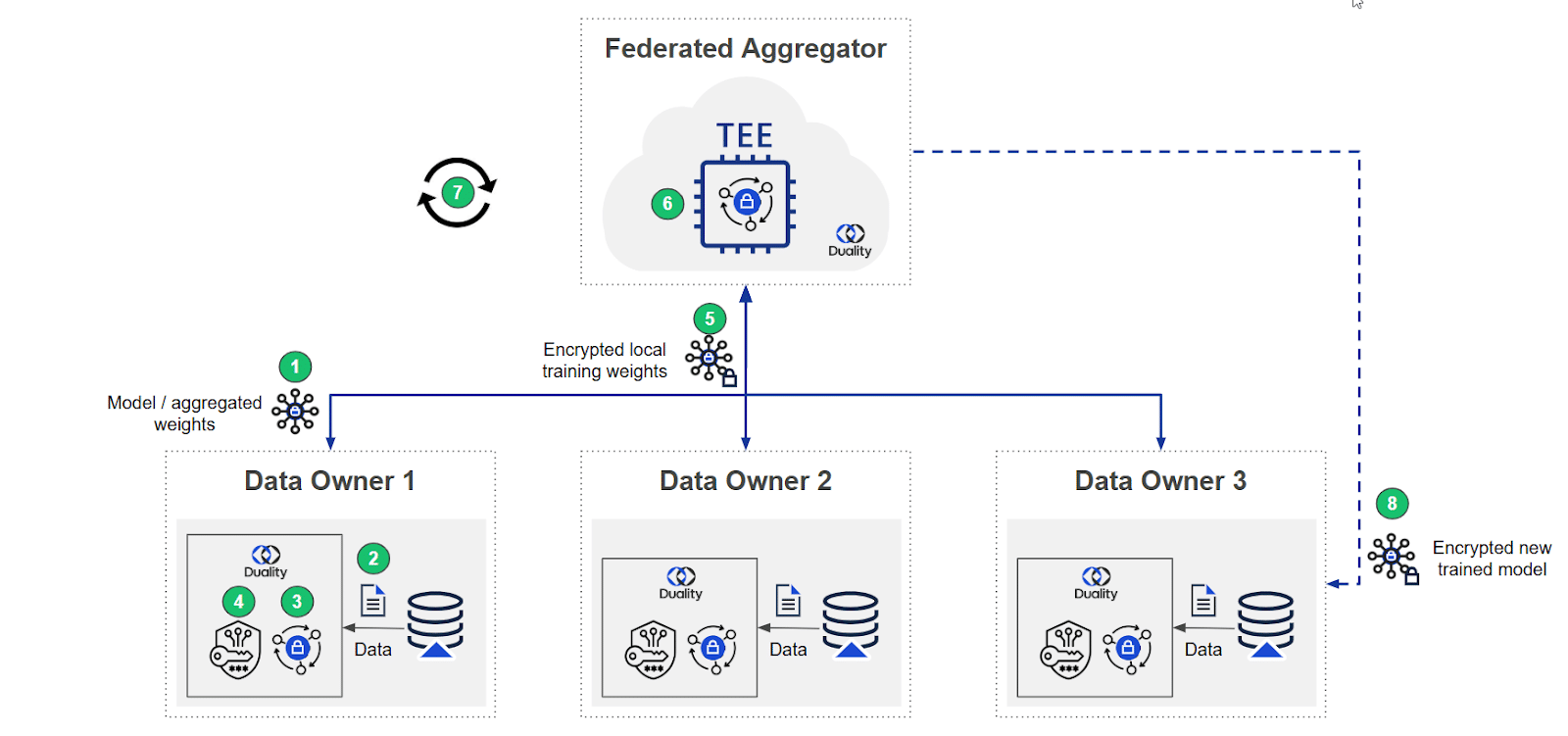
While in standard FL, local model updates are shared with a central server, this can expose sensitive patterns about the underlying data. Duality protects this aggregation step in two complementary ways:
- Trusted Execution Environments (TEEs): A TEE is an isolated area on the processor, separated from the system’s main OS. Computations occur inside this enclave, ensuring data is processed securely and is inaccessible to anyone including infrastructure providers.
- Fully Homomorphic Encryption (FHE): Allows computations to be performed directly on encrypted data, ensuring it remains encrypted throughout the entire computation lifecycle.
For a deeper dive, including a real-world use case, see our blog: Secure Federated Learning with NVIDIA and Google Cloud.
Differential Privacy
Even after secure aggregation, aggregated outputs can sometimes be reverse-engineered to reveal private details. To prevent this, Duality applies differential privacy, introducing mathematically calibrated noise that protects individual records from re-identification while preserving overall utility. Privacy parameters are configurable per use case, striking the right balance between protection and accuracy.
Governance by Design
Strong governance mechanisms ensure that data owners retain control over who can access their data, and for what purpose. Every computation is subject to explicit approval, with policies defining what is allowed, how often, and under what conditions. This prevents unauthorized inferences and protects against privacy erosion from repeated queries, while also aligning with regulatory demands for auditability and accountability.
Real-World Impact
This combination of FL and PETs enables secure collaboration across some of the most sensitive domains:
- Financial services: Major banks are collaboratively training fraud detection models without exposing account data. By pooling distributed intelligence, they can detect fraud patterns that no single bank could identify alone while preserving customer confidentiality.
- Healthcare: Hospitals and research partners have trained cancer-detection models on distributed patient images. Results matched the accuracy of centralized models, but no patient data was ever moved or exposed. This allows life-saving AI while meeting strict compliance requirements.
- Cross-border research: U.S. and U.K. institutions are conducting joint pediatric cancer studies using FL with PETs. For the first time, researchers can collaborate on highly sensitive data across jurisdictions without breaching sovereignty or regulatory boundaries.
Privacy as a Foundation, Not a Barrier
Duality’s federated learning platform demonstrates that privacy is not an obstacle to collaboration, it is the foundation that makes it possible. By combining a full-featured FL stack with embedded PETs, Duality enables organizations to unlock the value of distributed, sensitive, and regulated data while preserving confidentiality, sovereignty, and trust.



