

Shorten sale cycles, improve customer satisfaction, reduce churn, and expand business among AI teams.
Executive Summary
AI model development requires rigorous training and validation involving large volumes of diverse data to become effective, scalable, and valuable enough to make it out the door and into production. Fortunately, massive troves of data are available from data vendors and brokers. Naturally, before making a major purchase or commitment, the AI owners must verify that the data will be useful for their needs. Traditionally, this requires that either the Model Owner provide their model to the Data Provider to test on the data, or the Data Provider gives the AI Model owner access to the data. The problem is that neither side is okay with that access.
The data vendors must hold on to their valuable data until a sale, and the AI model owner must protect their IP (the models). In this article, we demonstrate a solution that simultaneously supports the privacy of the data and the model while allowing model owners to validate the usefulness of the dataset. Through a privacy-protected trial, data vendors can better satisfy security demands from AI teams and shorten sales cycles by providing an easy path to data validation.
AI, ML, and Data
AI and Machine Learning are growing exponentially, expanding to every corner of our business and personal lives in a way that can be both overwhelming and exciting. A thriving ecosystem of AI vendors and AI Engineering teams offer models to create efficiencies and uncover opportunities across all industries: government, finance, healthcare, manufacturing, retail, and more. These custom AI models offer powerful capabilities – from classification models that recognize and weed out the noise to regression models that can predict consumer trends based on product feature usage, marketing activities, or buying behaviors that make today’s predictions look pedestrian.
Like any growing entity, AI models must be fed. What do AI models eat? Data, of course. Luckily, the creation and storage of data was flourishing long before AI was on the horizon. The Worldwide IDC Global DataSphere Forecast, 2023–2027, estimates that 129 zettabytes will be generated this year, and that number will more than double by 2027. The existence of data is not the problem.
Data providers and brokers have massive data stores the AI models need. So, what’s the problem? Maintaining security and privacy of both the data and the model, which is a firm’s intellectual property (IP). AI teams commonly want or need to test their models on real data before making a significant data purchase and commitment—to ensure it will help improve business outcomes by evaluating the data for relevance, range of diversity, accuracy, trustworthiness, completeness, and bias. That’s a hefty list of requirements. But naturally, a data provider can’t simply give away this valuable resource to the AI teams, and the teams can’t hand over their proprietary models to the data provider to train on its sensitive data. There’s an impasse.
There is a better way: Duality’s Privacy Protected AI Collaboration solution. With the addition of Trusted Execution Environments (TEEs), or secure enclaves, the Duality Platform now supports entire data science workflows for teams developing or using advanced AI models. When it comes to the data provider’s role in supporting data ops for AI engineering teams, the platform:
- Streamlines sale cycles with faster trials and PoCs when introducing 3rd party data
- Reduces customer churn by allowing real validation pre-purchase
- Differentiates the Data Provider when addressing the growing segment of AI Engineering Teams
AI Engineers Need (Real) Data
Within the realm of designing, building, and delivering AI models, data isn’t just a passive component. Models are only as good as the data on which they’ve been developed and trained. The key to maturing model efficacy enough to move it from R&D to production-ready is vast quantities of real data at multiple stages of AI model training. In addition, models are reflective of the data used for training and development, which is another reason to have a way to protect the models during runtime. According to recent Gartner research, only 54% of models make it to production, and the challenges in dataops required by AI Engineering programs are a part of what holds many back.
Training Data:
The training data stage is where data is arguably the most critical: this is when a model establishes its foundational understanding. This dataset becomes the medium through which the model learns to identify patterns, associations, and correlations. The quality and diversity of the training data significantly influence the model’s ability to generalize and perform accurately in real-world scenarios. When obtaining or using real data is difficult due to privacy concerns, vendors may use “synthetic data” instead—artificially generated data that imitates the characteristics and patterns of real-world data. However, synthetic data can’t compete in terms of reflecting real-world complexity, diversity and variability, and mitigation of bias – and translating into business value.
Validation Data
Validation data aids in fine-tuning the model’s parameters to prevent overfitting or underfitting. By assessing the model’s performance on data not encountered during training, validation data ensures a delicate balance between acumen and adaptability. Synthetic data can sometimes be utilized in this stage.
Test Data
The test data phase serves as the ultimate assessment for any AI model. This dataset, unseen during training, challenges the model to apply its learning to new and unexplored territories. Evaluating the model’s performance on this independent dataset provides insights into its robustness, reliability, and generalization capabilities.
Many of these requirements can be met by working with a trusted data provider, but even trusted providers still need to confirm they can provide the appropriate data necessary for a specific AI Team’s (and model) needs.
Case Studies are Good, Fast Trials are Better
While case studies about other organizations utilizing similar datasets are helpful, they fall short of providing sufficient assurance that the data is appropriate for a particular organization with bespoke requirements. The efficacy of an AI model is intricately tied to the unique nuances of the data it has been trained on, and several factors contribute to establishing the fit of a dataset for a model:
Contextual Variability:
The suitability of data for an AI model depends heavily on the specific context, objectives, and intricacies of the model architecture. What works well for one application may translate differently to another, even within the same industry.
Model-Specific Requirements:
Different AI models have distinct data formats, quality, and relevance requirements. A dataset optimized for one model may lack crucial features or exhibit biases that hinder the performance of another model. Understanding the specific requirements of each AI model is essential, and relying solely on case studies may overlook these nuanced considerations.
Evolving Data Dynamics:
Datasets are dynamic entities that evolve over-time due to changes in user behavior, industry trends, or external factors. While a case study may provide a snapshot of successful model training at a specific point, it may not account for the evolving nature of the data. Ensuring ongoing relevance and suitability requires a nuanced understanding of how the data landscape changes.
Generalization Challenges:
AI models strive for generalization, the ability to perform well on unseen data. While case studies showcase successful outcomes in specific scenarios, the generalization capabilities of the models are not always apparent. Understanding how well a model adapts to diverse and previously unseen data is crucial for assessing its broader applicability.
Even assuming the data quality is outstanding and all other factors are equal, each AI model is unique, and a decision on the suitability of specific data couldn’t be reliably based on case studies alone. The best assessment requires a valid trial of real data.
SOLUTION: A Better, Faster, and More Secure Data Trial
By utilizing Duality’s privacy-enhanced data collaboration platform, data vendors and brokers can now offer a quick, fully-featured, yet fully secured and private data trial experience. Duality’s solution enables data use without data or model exposure, eliminating the two major challenges when AI teams seek out 3rd party datasets to use in development and training. Duality’s software features governance controls, reports, and data privacy and security guarantees throughout the secure data trial.
How a Secure Shared Data Trial Works
- Duality Secure Data Collaboration platform for the Data Provider
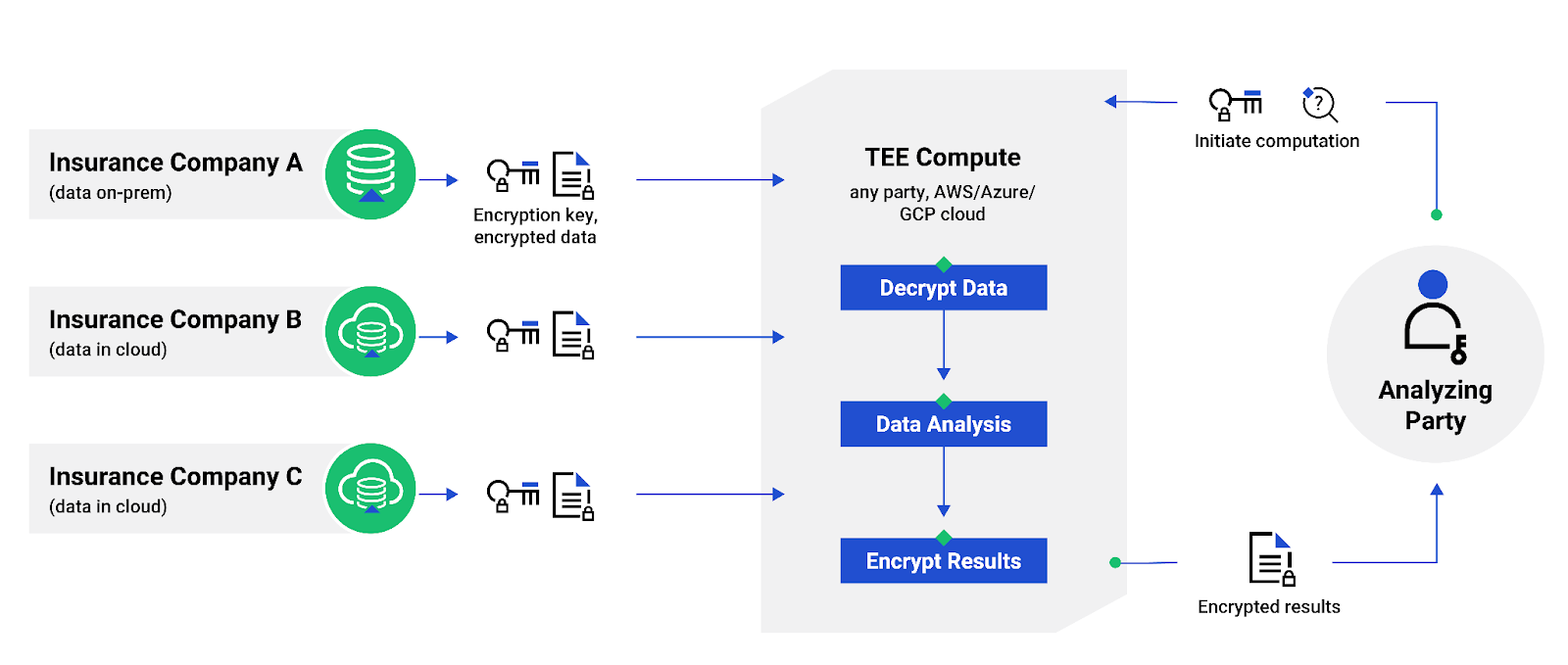
The Data Provider implements Duality’s Secure Data Collaboration platform, a cutting-edge solution designed to uphold the highest data security and privacy standards. The platform supports Trusted Execution Environments (TEEs) that act as a secure enclave, safeguarding sensitive data from external threats and providing a foundation for collaborative data processing.
- Duality Secure Data Collaboration Platform for the AI/ML Model Owner
The AI/ML model owner installs Duality’s privacy-enhanced software solution on their infrastructure (on-prem or cloud) and selects the model they want to run. The added support for TEEs allows model owners to protect their IP when running against 3rd party datasets.
- Onsite Encryption, Secure Transmission to the TEE
Prior to any data or model transmission to the TEE, both are encrypted directly at the source. This crucial step ensures the data and model remain confidential and secure during transit to the TEE.
- Attestation, Decryption, and Secure Computation in the TEE
Attestation for Trusted Execution Environments (TEEs) is a cryptographic process that allows a TEE to prove its integrity and authenticity to a remote party. Attestation allows remote parties to verify that the TEE is running the correct code and that it has not been tampered with.
Once the encrypted data and model arrive within the Trusted Execution Environment, the data/model are decrypted inside the TEE by using the keys that are accessible during the attestation process. This process ensures that although the process runs on the decrypted data, no one (including the cloud vendor admin) can access and view the data inside the TEE. This controlled environment allows for the execution of computations on the data while maintaining the utmost privacy and confidentiality without risk of exposure to external entities. This ensures that the sensitive nature of the data is preserved throughout the analytical process.
- Encrypted Result Transmission and Review
Post-computation, the results are encrypted in the TEE before being transmitted back to the Analyzer/Model Owner. Upon reaching the Analyzer’s environment, the results are decrypted, allowing the Analyzer to review and interpret the outcomes. The end-to-end encryption and decryption processes encapsulate the entire lifecycle of data collaboration, assuring both parties that the sensitive information remains confidential and intact and that the model itself is never exposed.
Duality’s Secure Data Collaboration platform demonstrates the fusion of cutting-edge technology and stringent security measures. Embedding privacy at every stage ensures that collaborative data analysis can be performed with trust in the confidentiality of both the proprietary AI model and the precious data.
Conclusion
Whether it’s image recognition, natural language processing, or predictive analytics, AI models are conquering new fields seemingly every day. The sophistication of these models ranges from the rudimentary to the intricate, depending on the complexity of the task at hand. But all require data, and now there’s an easier way to test and provide the exact data AI model vendors need.
Data Providers/Brokers benefit from:
- Shorter sale cycles via fast, secure, and private data trials.
- Reduced customer churn.
- Market advantage when serving AI Teams, a fast-growing market
AI Teams benefit from:
- Faster time to market
- Privacy-protected data ops to support AI Engineering efforts
Have more questions? Contact us to discuss how this solution will help your organization benefit from the AI Gold Rush.
In our next blog we’ll discuss how the Duality AI solution helps streamline sales for AI Developers by allowing proprietary AI models to be customized and trialed with customer data while maintaining the privacy and security of both the customers’ data and the model.


