
Inference models offer tremendous potential for businesses to gain insights and boost revenue. But let’s face it: creating and profiting from these machine learning models isn’t a walk in the park. It takes a mix of technical know-how, smart strategy, and an understanding of the market.
So, what challenges might you face when you’re developing and monetizing inference models? We’ll break down the process of developing these models, from dealing with data and model IP protection challenges to personalizing algorithms. Then, we’ll tackle the business side of things and what challenges you might face when monetizing your model.
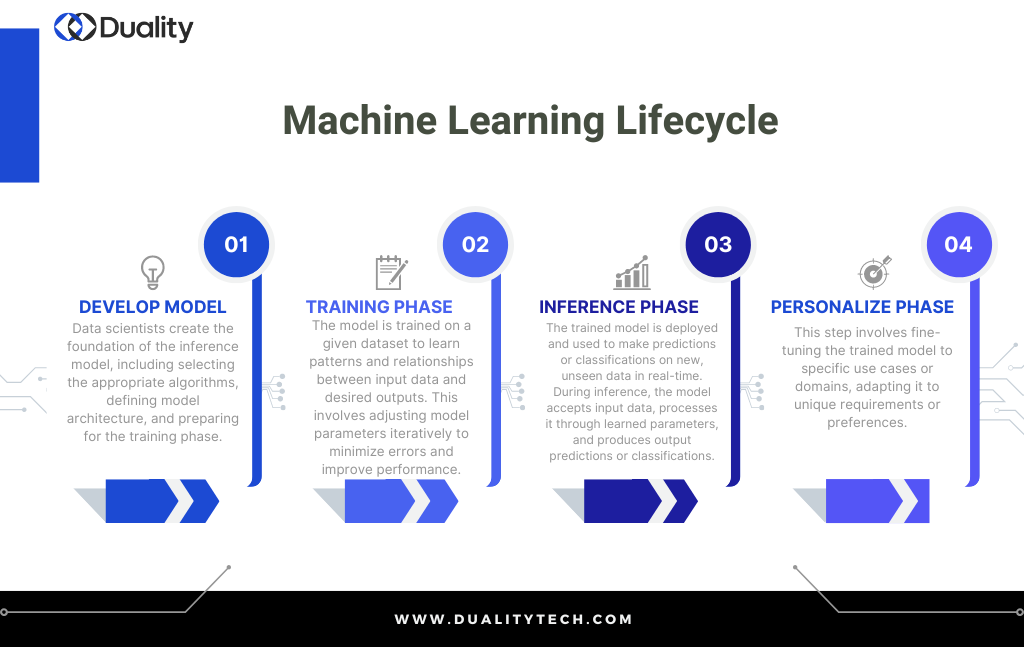
The machine learning life cycle includes two critical processes. The first is the training phase where a created model is trained on a given dataset and then tested with an example dataset. The second is the inference phase. Inference is the process that involves using the trained model on real data to produce real outputs. This phase consists of the deployed model accepting a request, processing the learned data, and providing an output post-request. Using a similar example to the one we discussed in our previous blog, let’s walk through the machine learning lifecycle:
Imagine you work for a financial institution that wants to improve its fraud detection system and provide better customer service for your clients. You decide to develop an inference model to predict fraudulent transactions.
During the training phase, you collect historical transaction data from the bank’s databases. Using this data, you train the model to recognize patterns and anomalies associated with fraudulent transactions. The model learns to identify suspicious activities by analyzing various factors such as transaction frequency, amount, and deviation from typical customer behavior.
Once the model is trained and validated, it can be deployed to analyze incoming transactions in real time. For example, when a customer makes a purchase or initiates a transaction, the model can assess the transaction’s risk level based on its characteristics and the customer’s historical behavior. If the model detects a high likelihood of fraud, it can trigger an alert for further investigation by the bank’s fraud detection team.
So, think of model training as the extensive study period before an exam and the inference or prediction phase as when the learned knowledge is put to the test, in real-time, on real-world problems.
While developing an inference model, the primary challenges relate to gathering and using data without compromising privacy. It’s important to train and test your model on accurate and high-quality data without exposing it to sensitive information.
Effectively developing an inference model relies heavily on the data you’re able to use. Failing to efficiently manage 3rd party data compromises the model’s security and trust, impacting its ability to generate accurate and actionable insights. This will significantly reduce the model’s marketability and potential for generating revenue.
The first challenge is gathering enough high-quality training data for your model, which typically requires a third party. Obtaining such data sets can be daunting and often requires extensive resources and efforts to gather, clean, and preprocess the data effectively. Without sufficient and reliable data to train the model, the model’s ability to produce accurate predictions may be compromised.
After the initial training phase, the model must be tested and validated before deployment. Testing and validating the efficacy of inference models also demands access to high-quality data sets that accurately represent real-world scenarios. Without robust testing procedures and high-quality data, it becomes challenging to assess the model’s performance accurately and identify potential shortcomings or biases. But, data privacy and confidentiality concerns still apply. It’s crucial to minimize the risks of data breaches at every step in the lifecycle.
Monetizing your model allows for revenue generation, market expansion, and competitive advantage, attracting funding, partnership opportunities, and validation of your technology’s value and market potential. By leveraging your intellectual property, you can reach new markets, attract investors, and establish yourself as a leader in the industry, driving growth, innovation, and success for your business. But, how do you make it usable for different industries and how do you protect your work?
Personalizing an inference model involves fine-tuning model parameters, features, and algorithms to align with industry-specific trends, preferences, and regulatory requirements. However, achieving this level of customization requires access to relevant and domain-specific data sets, which may not always be readily available due to regulatory requirements as found in GDPR and ADPPA. These regulations, while essential for protecting individual privacy, make it difficult for to acquire and apply the data needed to personalize models.
The originality and creativity of your ML model provide value, and therefore it should be protected.
Without adequate protection, there’s a risk of competitors replicating or reverse-engineering your model, diluting your competitive advantage and potentially undercutting your market position.
The lack of IP protection could negatively impact your ability to monetize your inference model through licensing agreements, partnerships, or sales of the model itself. By establishing clear ownership rights and protections for your model’s IP, you can negotiate more favorable terms and maximize the value derived from monetization efforts.
Additionally, IP protection is essential for establishing and maintaining trust with clients and investors. If your model’s IP is not adequately protected, potential clients may be hesitant to invest in or license your technology, fearing that their investment may not be adequately safeguarded against unauthorized use or exploitation by competitors.
Organizations want to be able to share models and insights but must navigate the fine line between customization and compliance, ensuring they use the full potential of their data without overstepping legal boundaries and risking a competitive disadvantage. This is where secure collaboration AI can help. It revolutionizes how organizations handle sensitive data for developing, training, and monetizing machine learning models.
At Duality Tech, we have built the necessary infrastructure with the expertise of world-renowned cryptographers and data scientists, ensuring our secure collaborative AI solutions are innovative, credible, and trustworthy. This trust is cemented by our partnerships with leading entities such as AWS, DARPA, Intel, Google, Oracle, IBM, and the World Economic Forum (WEF), all of whom recognize our dedication to enhancing the value of data securely. By ensuring that sensitive information, personally identifiable information (PII), and intellectual property (IP) remain protected, our secure collaborative AI solution addresses the challenges of customer privacy and security head-on.
Here’s how it works – By utilizing security and privacy technologies, Duality’s secure collaborative AI solution provides technical guardrails to protect the model IP and input data from everyone but the owners. The software features governance controls, reports, and data privacy and security guarantees for both the model and data owners. Therefore, the data brokers do not have access to the IP and the model developers do not have access to the sensitive information.
Elevate your data privacy measures and establish a more secure and robust data management framework. Contact us to explore how our cutting-edge solutions can benefit you today!













