

In financial services, visibility determines the quality of every decision.
Each institution holds detailed internal data: transactions, behavioral signals, and risk indicators. Yet the patterns that matter most rarely exist within a single organization. They emerge across banks, payment networks, and jurisdictions.
Fraud schemes span multiple institutions. Money laundering flows move through layered accounts across borders. Credit risk depends on borrower behavior that extends beyond a single lender’s view.
Detection, however, is still largely confined within institutional boundaries.
This creates a structural gap. Institutions are accountable for identifying and managing risks that extend beyond their own data, while the information required to fully understand those risks remains fragmented.
Financial AI initiatives slow down because they operate with an incomplete view of the system they are meant to analyze.
Why Financial Services AI Stalls: The Visibility Gap
Financial risk operates across networks, while detection systems operate within institutions.
Fraud detection systems perform effectively within a single bank, but coordinated attacks are designed to bypass those boundaries. A mule account in one institution, a transfer through another, and a withdrawal elsewhere can appear legitimate when viewed in isolation.
AML monitoring faces similar limitations. Suspicious behavior often depends on transaction flows that span multiple entities, accounts, and jurisdictions. When those flows are fragmented, detection becomes less reliable.
Credit models are also constrained. Lenders evaluate borrowers based on partial histories, without visibility into broader exposure or behavior across institutions.
These limitations directly affect outcomes. Detection rates are reduced, false positives increase, and risk is distributed in ways that are difficult to track or quantify.
The Structural Constraint: Regulation, Risk, and Competition
Financial institutions operate within a set of constraints that are not incidental, they shape how data can be used, shared, and governed at every level. These constraints are interconnected, and together they define the limits of traditional collaboration models.
- Regulatory constraints and data sovereignty:
Financial data is subject to strict regulatory oversight, including privacy laws, banking regulations, and jurisdiction-specific requirements. Customer data often cannot be transferred freely across borders, and even within a country, usage is tightly controlled. Institutions must demonstrate not only compliance, but also auditability, knowing exactly how data is accessed, processed, and shared at all times. - Risk exposure and compliance obligations:
Any movement or sharing of data increases exposure. This includes risks of data breaches, misuse, re-identification, and regulatory violations. Compliance frameworks require institutions to minimize these risks, which makes large-scale data sharing difficult to justify, even for high-value use cases like fraud detection or AML. - Competitive and strategic considerations:
Data is not just an operational asset, it is a source of competitive advantage. Transaction histories, fraud patterns, and credit behaviors are core to how institutions differentiate their services and manage risk. Sharing raw data introduces the possibility of losing proprietary insights or exposing internal strategies to competitors. - Operational and technical complexity:
Financial institutions operate on heterogeneous systems with different data models, formats, and infrastructures. Aligning these systems for collaboration requires significant effort. Legal agreements such as data-sharing or data-use agreements can take months to negotiate, and implementing secure data pipelines adds further cost and complexity.
These factors reinforce each other. Regulatory requirements increase risk sensitivity, risk concerns limit sharing, competitive dynamics discourage openness, and operational complexity slows everything down. As a result, traditional approaches to collaboration, based on pooling and centralizing data, struggle to scale in financial services, even when the need for collaboration is clear.
The Shift: From Data Sharing to Network Intelligence

A different model is emerging, focused on enabling analysis across institutions without requiring data movement and demonstrating how financial systems are designed to generate insight.
In this approach, data remains within each institution’s environment, under existing controls, policies, and regulatory frameworks. Instead of aggregating data into a central system, computation is distributed outward. Each institution runs analytics locally, and only the outputs, signals, model updates, or aggregated results, are shared in a controlled and governed way.
This changes the unit of collaboration. Instead of sharing data, institutions contribute computed intelligence.
Several key characteristics define this model:
- Computation moves to data, not the other way around:
Analytical tasks, whether fraud detection rules, AML typologies, or model training, are executed within each institution’s secure environment. This avoids the need to replicate or transfer sensitive datasets. - Local control is preserved by design:
Each organization retains full authority over its data, including what computations are allowed, how outputs are filtered, and what leaves the environment. Governance is enforced at the source rather than after aggregation. - Only minimal, controlled outputs are shared:
Instead of exposing raw transactions or customer records, institutions share encrypted signals, statistical summaries, or model parameters. These outputs are designed to be useful for collective analysis while remaining non-sensitive. - Aggregation happens securely across participants:
Outputs from multiple institutions are combined using secure aggregation techniques, often within protected environments. This allows cross-institution patterns to emerge without revealing any individual dataset.
This architecture enables what can be described as network intelligence.
Financial risk signals rarely exist in isolation. Fraud patterns emerge across accounts and institutions. AML behaviors depend on transaction flows that cross borders and entities. Creditworthiness is influenced by behavior across multiple lenders. When these signals are analyzed collectively, their strength and clarity increase significantly.
Under traditional models, these connections remain hidden because data cannot be brought together. In a distributed model, those connections can be inferred without exposing the underlying data.
This shift expands what institutions can observe:
- Fraud detection moves from isolated alerts to coordinated pattern recognition
- AML monitoring gains visibility into multi-entity transaction flows
- Credit models incorporate broader behavioral signals without centralizing borrower data
Importantly, this expansion of visibility does not require a change in how data is governed. Data remains subject to the same regulatory, security, and operational controls as before. What changes is how that data is used through coordinated computation rather than direct access.
The result is a model where institutions can act on network-level signals while maintaining institution-level control.
What Are Privacy-Enhancing Technologies (PETs)?
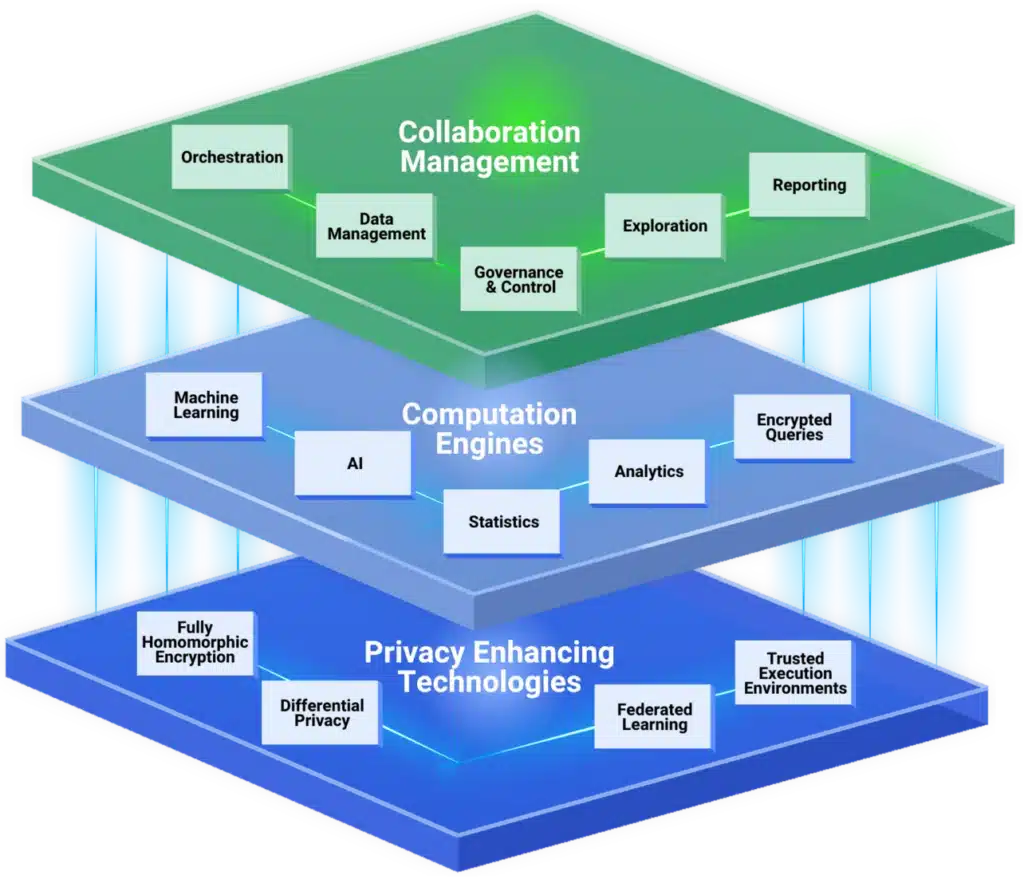
Privacy-enhancing technologies (PETs) enable secure computation across distributed datasets. They ensure that sensitive financial data remains protected not only at rest and in transit, but also during analysis.
In the context of this article, PETs are what make network-level intelligence possible under real-world financial constraints. The visibility gap described earlier exists because institutions cannot move or share data freely. PETs address that constraint directly by allowing institutions to analyze data where it resides while still contributing to a shared outcome.
Without PETs, the shift from isolated detection to network intelligence would not be operationally feasible. They provide the technical foundation that allows institutions to:
- Detect cross-institution fraud patterns without exposing transaction data
- Analyze AML flows across entities while maintaining regulatory compliance
- Improve credit models using broader signals without centralizing customer data
Key technologies include:
- Federated learning architecture, which enables model training across institutions without moving data
- Differential privacy, which ensures outputs do not reveal individual-level information
- Trusted execution environments (TEEs), which isolate and secure computation
- Homomorphic encryption, which allows computation on encrypted data
These technologies work together to support secure, cross-institution analytics while preserving data control. More importantly, they remove the core limitation outlined in this article: the inability to use data that cannot be shared.
By enabling computation without exposure, PETs allow financial institutions to operate with broader visibility while staying within regulatory, security, and competitive boundaries.
How PETs Enable Network-Level Detection
Financial signals become significantly more meaningful when analyzed across institutions.
PETs allow organizations to move from isolated analysis to coordinated detection.
In fraud detection, institutions can identify patterns that span multiple banks without sharing transaction-level data. Signals are analyzed locally and aggregated securely.
In AML, transaction flows across entities can be evaluated to identify structuring and layering behaviors.
In credit modeling, federated learning architecture allows models to incorporate broader behavioral signals while maintaining data ownership.
| Collaboration Stage | What Needs to Happen | PETs Involved |
| Signal Discovery | Identify cross-institution patterns | Secure querying, encryption |
| Analytics | Detect behaviors locally | TEEs, privacy-preserving computation |
| Model Training | Build shared models | Federated learning architecture |
| Output Sharing | Share insights safely | Differential privacy |
This approach enables institutions to operate with a more complete understanding of risk.
Real-World Use Case: Cross-Institution Fraud Detection
Coordinated fraud highlights the limitations of isolated detection systems.
A typical scheme may involve accounts across multiple banks, transactions routed through different systems, and withdrawals executed through separate channels. Each institution observes a portion of the activity.
Without broader visibility, these patterns are difficult to identify.
With a federated, PET-based approach, each institution analyzes its data locally. Signals are encrypted and aggregated securely, and models are trained across institutions without exposing raw transaction data.
This enables detection of coordinated activity that would otherwise remain fragmented.
Insight
Financial crime operates across institutions. Detection improves when analysis reflects that structure.
Putting PETs into Practice in Financial Environments
Implementation begins with clearly defined use cases.
Fraud detection, AML monitoring, and credit modeling each require different signals and workflows. Institutions define what needs to be computed and where that computation should occur.
Federated learning architecture supports model training, while other PETs enable secure analytics and querying.
Coordination across institutions is essential. Policies define how computations are executed, how outputs are shared, and how governance is enforced.
Insight
Effective systems are designed around distributed computation aligned with data boundaries.
Why This Problem Looks Different Depending on Your Role
The visibility gap is shared across the organization, but it manifests differently depending on each function’s responsibilities and constraints.
- Fraud and Financial Crime Teams:
Detection systems are tuned to identify suspicious activity, but coordinated fraud schemes are intentionally distributed across institutions. Signals appear benign in isolation, which delays detection until downstream indicators emerge. Teams often respond to fraud after it has already propagated, rather than identifying it at the network level. - AML and Compliance Teams:
Regulatory frameworks require detection of complex transaction patterns such as layering and structuring. These patterns frequently span multiple institutions and jurisdictions. Compliance teams must meet strict expectations while working with fragmented visibility, creating ongoing pressure between regulatory accountability and practical limitations. - Risk and Data Science Teams:
Models are trained on institution-specific data, which limits their ability to capture broader behavioral patterns. This affects predictive accuracy and complicates validation. Model risk increases when datasets do not fully represent the environments in which decisions are made. - Security and Data Governance Teams:
Protecting sensitive financial data is the primary objective. Any effort to share or move data introduces potential exposure, whether through breaches, misuse, or regulatory violations. Governance frameworks are designed to minimize these risks, which constrains how collaboration can occur. - Executive Leadership (CRO, CIO, CDO):
Leaders are responsible for managing systemic risk, regulatory compliance, and operational performance. They must address threats that extend beyond institutional boundaries while maintaining strict control over data and infrastructure. This creates a strategic challenge where accountability exceeds visibility.
Across all roles, the same constraint applies. Financial risk is distributed across networks, while data remains siloed within institutions.
Building Scalable Financial Data Collaboration
Financial ecosystems include banks, payment networks, regulators, and consortiums.
PET-based approaches allow these participants to contribute to shared intelligence without exposing sensitive data or compromising competitive advantage.
Each institution retains control while participating in distributed computation. This enables collaboration to scale across networks without introducing new risks.
As participation increases, detection capabilities improve through broader coverage and more complete visibility.
The Deeper Shift: From Trust to Enforced Control
Traditional collaboration relies on agreements to define how data should be handled.
PETs embed these controls into the system itself.
Data remains within institutional boundaries. Computation follows defined policies. Outputs are governed before being shared.
This creates a model where collaboration is enforced through architecture, reducing reliance on trust between participants.
What To Do When Critical Data Sits Outside Your Organization
Many organizations recognize that key signals exist beyond their own systems.
The next step is to identify where visibility gaps impact outcomes, whether in fraud detection, AML monitoring, or credit modeling.
Workflows are then designed to operate across distributed data. The focus shifts to defining required computations and ensuring they can be executed securely.
PETs enable these workflows by allowing analysis without data movement.
Initial implementations often focus on targeted use cases with measurable impact. These can then expand into broader frameworks for network-level intelligence.
Conclusion
Financial services operate in an environment where risks extend across institutional boundaries.
Privacy-enhancing technologies, combined with federated learning architecture, enable institutions to analyze those risks without exposing sensitive data.
This approach supports more effective fraud detection, stronger AML monitoring, and improved credit modeling.
Organizations that adopt these models gain a clearer view across the financial system while maintaining control over their data.


